Introduction:
In the field of machine learning, the XGBoost algorithm has emerged as a powerful tool for tackling regression problems. Its ability to handle complex, non-linear relationships, along with its efficiency and scalability, has made it a go-to choice for many problems. Additionally, the algorithm's performance can be further enhanced through hyper-parameter tuning using techniques like Grid Search Cross-Validation (CV). In this blog post, we will explore the importance of the XGBoost algorithm and delve into the advantages it offers for regression problems, along with the benefits of hyper-parameter tuning using Grid Search CV.
Understanding XGBoost:
XGBoost, short for "Extreme Gradient Boosting," is an ensemble learning algorithm that combines the strengths of decision trees and gradient boosting. It builds an ensemble of weak prediction models (typically decision trees) and iteratively improves their predictions by minimizing a loss function through gradient descent. This iterative process creates a strong predictive model capable of capturing complex interactions within the data.
Advantages of XGBoost for Regression:
Handling Non-linearity: XGBoost excels at capturing non-linear relationships in the data. Traditional linear regression models may struggle with complex interactions, but XGBoost's ability to build a series of decision trees allows it to model non-linear patterns effectively.
Feature Importance: XGBoost provides valuable insights into feature importance. By analyzing the impact of each feature on the model's performance, we can gain a deeper understanding of the underlying data and extract valuable insights.
Regularization: XGBoost includes regularization techniques, such as L1 and L2 regularization, to prevent overfitting. These techniques help control the complexity of the model, ensuring it generalizes well to unseen data.
Cross-Validation
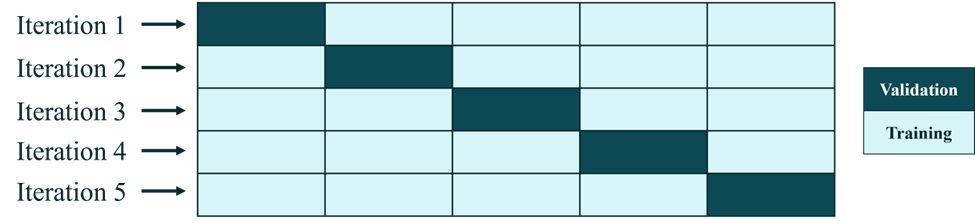
Cross-validation is a technique used in machine learning to evaluate the performance and generalization ability of a predictive model. It involves splitting the available dataset into multiple subsets or ‘folds’ to train and test the model iteratively. It provides a more reliable estimate of performance, enables efficient use of data, facilitates hyper-parameter tuning, and aids in model selection. By leveraging cross-validation, we can build more robust and reliable machine learning models.
Here is a schematic diagram of how CV works when folds = 5:
Hyper-parameter Tuning with Grid Search CV:
Hyper-parameters are crucial settings that affect the behavior and performance of machine learning models. Finding the optimal combination of hyper-parameters can significantly enhance model performance. Grid Search CV is a technique that systematically searches for the best hyper-parameter values within a predefined range.
Exhaustive Search: Grid Search CV explores all possible combinations of hyper-parameter values specified in a grid or search space. It systematically evaluates each combination by performing cross-validation on the training data. This exhaustive search ensures no potential set of hyper-parameters is overlooked.
Performance Evaluation: Grid Search CV evaluates models based on a chosen performance metric, such as mean squared error (MSE), mean absolute error (MAE) or R-squared. By comparing the performance of different hyper-parameter combinations, it helps identify the configuration that yields the best results.
Avoiding Overfitting: Grid Search CV helps prevent overfitting by validating models on unseen data through cross-validation. By splitting the training data into multiple folds and evaluating the model on each fold, it provides a more reliable estimate of the model's performance.
Time and Resource Efficiency: Although Grid Search CV exhaustively searches the hyper-parameter space, it benefits from parallel computing, which speeds up the process. Furthermore, by evaluating the performance of different hyper-parameter combinations, Grid Search CV helps optimize models without unnecessary experimentation, saving time and computational resources.
Conclusion:
XGBoost algorithm stands out as a versatile and effective tool for regression problems. Its ability to capture complex relationships, handle non-linearity, and provide valuable insights into feature importance makes it a top choice for several problems. However, to unlock its full potential, hyper-parameter tuning is crucial. Grid Search CV offers a systematic and efficient approach to finding the optimal combination of hyper-parameters, resulting in improved model performance. By leveraging XGBoost and hyper-parameter tuning using Grid Search CV, we can build robust regression models that yield accurate predictions and valuable insights for decision-making.
-4.png?width=120&height=120&name=MicrosoftTeams-image%20(3)-4.png)