Streamline Seismic Interpretation with Advanced Well-Tie
Random Forest (RF) is a supervised machine learning algorithm used in both classification and regression problems. It was an added function to the Deep QI license for RokDoc 2023.1!
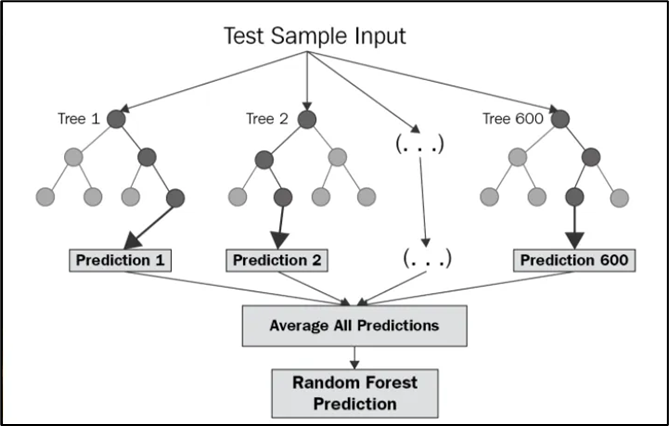
RF improves on the concept of a single decision tree by employing random feature selection and ensemble learning. Using multiple decision trees with random feature selection helps promote the utilization of all available features (contrary to a single decision tree) and guarantees that the root node - which has a huge influence - does not always remain the same.
Here is a photo of several trees in a random forest. Well, not really! This is from Sequoia National Forest :-) Consider each tree as a separate model and each tree is comprised of different data samples drawn from a training set.

The core concept behind this algorithm is that: many relatively uncorrelated trees operating as a group will perform better than any of the individual trees. Hence, the decision is taken as the tree-majority vote for classification and the average for regression tasks.
Mohsin Abdulazeez, Adnan & Falah, Yusur & Ahmed, Falah & Zeebaree, Diyar. (2021). Intrusion Detection Systems Based on Machine Learning Algorithms.
Data preparation
The input features/attributes must be chosen carefully such that they do better than random guessing in predicting the target variable. In the case of using Vp, Vs & Rho for predicting Porosity, the Vp, Vs & Rho are the input features and Porosity is the target variable. When representing the training dataset as a data frame with columns being input features and rows being data samples, random feature selection can be seen as random selection of data columns.
Additional variability of the trees is commonly achieved by random sampling with replacement of rows (referred to as bootstrapping). Thus, each tree in the forest ‘sees’ a randomly selected portion of data and operates with a randomly selected subset of features.
Advantages
The above approach leads to many relatively uncorrelated models operating as a committee which helps in reducing the overall variance, prediction error and the risk of overfitting. Unlike the case of a single tree, increasing complexity of a random forest model by adding more and more trees may not result in overfitting. This can be explained by the fact that, at some point of adding more trees, unique trees that operate with unique subsets of data and features will no longer be produced. Instead, the trees will simply repeat themselves, which will result in the lack of further improvements but not having a harmful influence.
Compared to deep neural networks, RF is computationally less expensive and requires much less data (approximately 5 wells or less depending on the dataset) to establish a robust predictive model.
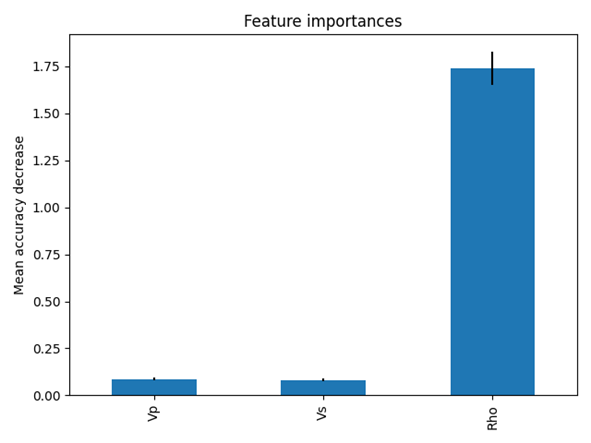
Besides, RF allows for efficient estimation of feature importance which shows the power of each input log-type in prediction of the target variable and, thus, facilitate the interpretation of results and provide user with useful insights. Here’s an example showing the importance of density in predicting porosity of a formation.
Conclusion
RF is one of the most popular and commonly used algorithms for both regression and classification tasks. The algorithm is great for small datasets. It can also handle very large datasets, but complexity in model building and the training time may increase. Depending on the problem/dataset in hand the RF has several benefits compared to decision trees or deep neural networks. It is a great choice if you want to build a model fast and efficiently.
For more information, please see the RokDoc Platform Add-ons section of our website.
-4.png?width=120&height=120&name=MicrosoftTeams-image%20(3)-4.png)


-1.png?width=500&height=500&name=MicrosoftTeams-image%20(11)-1.png)